威胁情报系列(二):威胁情报从哪里来
前言
上一篇文章中,我们介绍了什么是威胁情报,以及威胁情报相关的一些概念。
威胁情报在国内作为一个新兴事物,除了专业的乙方厂商,普通安全从业人员可能对其了解没有特别深入。导致了其在使用起来效果不甚明显,难以真正落地等问题。有很多甲方厂商都只是简单从网上收集未经筛选的开源情报直接使用,甚至有些小的乙方安全厂商的安全产品中也是如此使用威胁情报。希望通过本系列的介绍之后,大家能够把威胁情报技术真正运用到实际的安全工作中。
这里需要再次说明,本系列文章所讲诉的“威胁情报”为 IOC 情报,不包括广义上的攻击情报和漏洞情报等。各家 src 收集业务漏洞时所称的情报属于广义上的威胁情报,和我们要描述的内容无直接关系。不过在下一篇“威胁情报怎么用”中,我们将通过结合安全产品、和威胁情报所使用的大数据、实时计算等技术来将狭义的 IOC 情报所涉及到的技术扩展到安全防御的各个环节。
在本文中将从乙方威胁情报厂商视角讲一下威胁情报具体是怎么收集、生产、运营的,以及结合上篇文章中的基本概念简单介绍如何使用。通过了解专业团队是如何做可以加深对威胁情报本身的理解,以指导如何落地。
本文所指的乙方为国内比较有代表性的威胁情报厂商,如:腾讯御见威胁情报中心,奇安信威胁情报中心 以及 微步在线 等。
威胁情报的自带属性之一就是共享,除了商业威胁情报厂商之外还有很多开源的情报社区,但是上面也有提到,开源社区的情报质量良莠不齐,大多靠社区中的热心安全研究员贡献,缺乏有效的运营手段,直接使用效果不佳。而商业威胁情报厂商有其特有的数据和渠道,并且有比较严谨的运营流程。但是商业 IOC 除了部分公开的分析文章中可以免费获取,其余都需收费才可使用。对于没有充足经费的乙方厂商,可以借鉴其生产、运营手段,利用开源的社区情报也可以获得一些的效果。
下面将从生产和运营两个方面开始介绍商业威胁情报厂商的业务流程。
生产
威胁情报做为数据类产品,其生产流程和其他的数据类产品类似,都是先采集数据、处理数据、提取属性存入数据仓库、编写工程代码进行大数据处理,然后总结出专家经验后做出对应的自动化脚本,等到积累的样本足够多时便可以选择合适的机器学习算法构建模型。

图 1-0 生产流程
让我们先回顾一下上一篇中提到过的威胁情报的层次中的痛苦金字塔,威胁情报的生产也可以参考该图来说明。
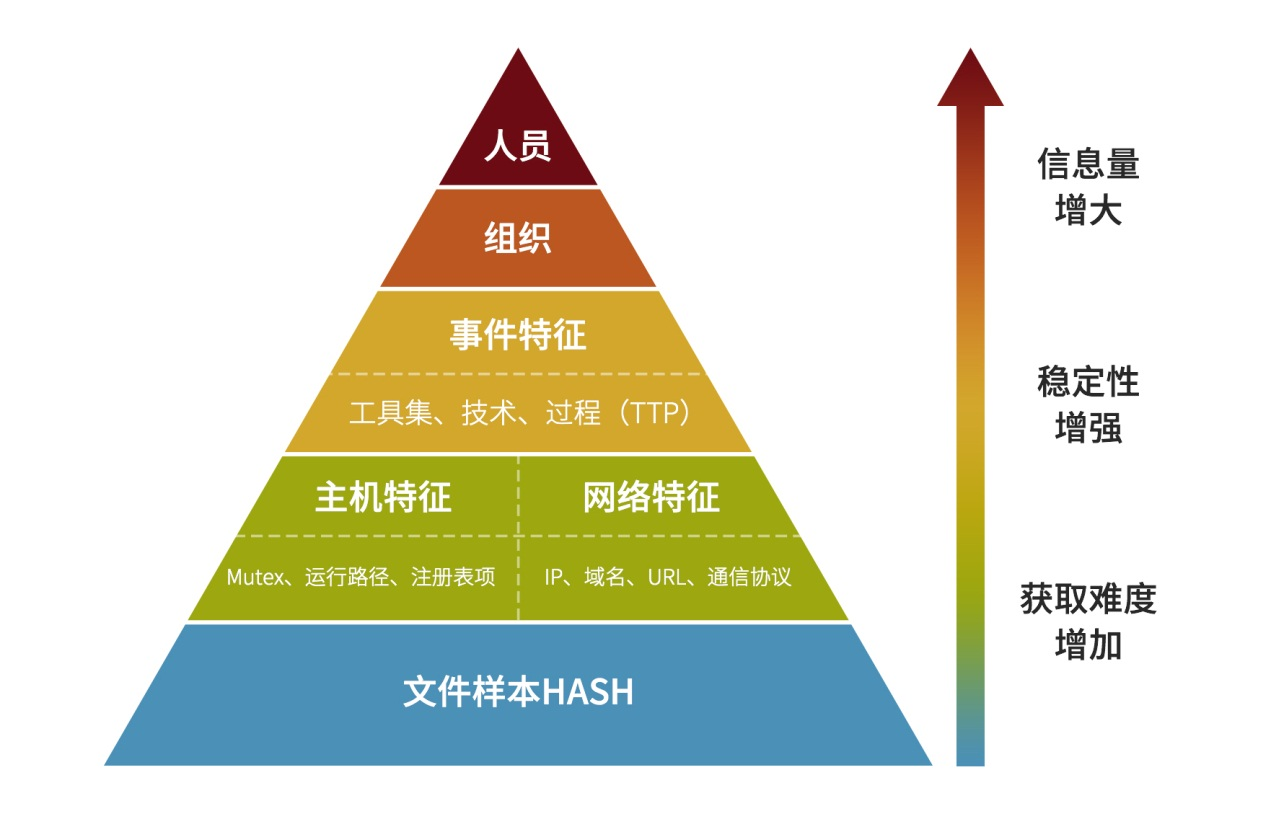
图 1-1 威胁情报的层次
可以看到金字塔最底层的为文件样本 hash (这里的文件包括各个平台上的执行文件,doc 文档,js、vbs 脚本等等)。威胁情报业务也是从样本出发。
样本层面
最原始的威胁情报即为杀毒软件厂商的病毒库,安全研究人员的样本分析文章,Vitrustotal 类多引擎查杀结果,Hybird Analysis 类在线沙箱等可以公开或者花钱购买到的恶意样本信息,而该类信息通常是由 hash 的形式提供(md5、sha1、sha2 等等)。
更深度的情报信息一般需要从样本出发加工,所以威胁情报业务的第一步即为收集尽量多的样本数据。
样本收集
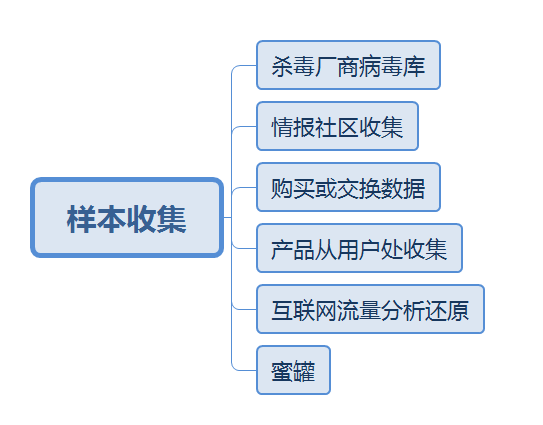
图 1-2 样本收集渠道
上面提到的奇安信和腾讯都有自己的杀毒软件(奇安信的前身为360企业安全,有360卫士的数据),并有自己的病毒库。而微步模仿 Virustotal 做了在线沙箱,并提供样本上传后多引擎鉴定的能力,通过社区网站可以收集到很多个人提交的样本。
除了从社区被动收集,还可以通过数据交换来获取更多样本数据,比如给 Virustotal 提供沙箱引擎可以获得 Virustotal 反馈的数据,或者加入微软、IBM等厂商的情报交换系统,以及爬取开源社区的数据等等。
一些厂商的安全产品在用户许可的情况下也可以获取部分数据,比如企业级的终端杀毒产品、EDR产品,以及可以还原流量中的文件的NTA产品等。NTA类的产品还可以和运营商合作使用流量分析技术还原互联网流量中的文件数据。
建立蜜罐系统也可以收集到投递进蜜罐的样本。
样本鉴定
获取了足够多的样本后,接下来则是需要鉴定样本。这里的鉴定除了鉴定样本是否恶意(黑、白、灰)之外,还需要能给出样本的病毒名(包括家族名)。
如 VT 上的这个 Sality 样本

图 1-3 示例 Sality 病毒名
病毒名 TrojanDropper:Win32/Sality.AU 中,TrojanDropper 是样本的恶意类型,即”木马投递”,Win32 描述病毒的针对的平台,即 Windows,Sality 是为了方便用户和病毒分析人员记忆取的名字,就像国内的病毒取名叫“熊猫烧香”一样。
鉴定恶意软件样本的方法一般有静态和动态两种类型。两种方法的输入都是样本文件,输出一般为文件的指纹(一般为 hash)。
建议阅读《恶意代码分析实战》进行更多了解。
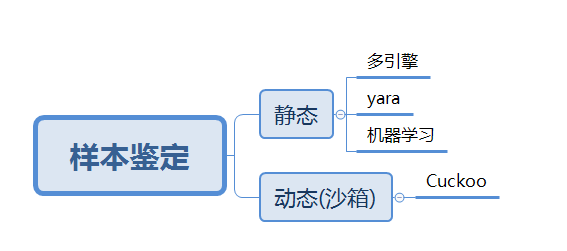
图 1-4 样本鉴定
静态鉴定
现在的静态鉴定常用的手段是使用云端多引擎查杀技术,即将新出现的疑似恶意的文件上传到云端,使用多个杀毒引擎同时对其鉴定。
例如上面引用的 Sality 样本,在 VT 上显示 71 个杀毒引擎有 65 个将其判断为恶意。
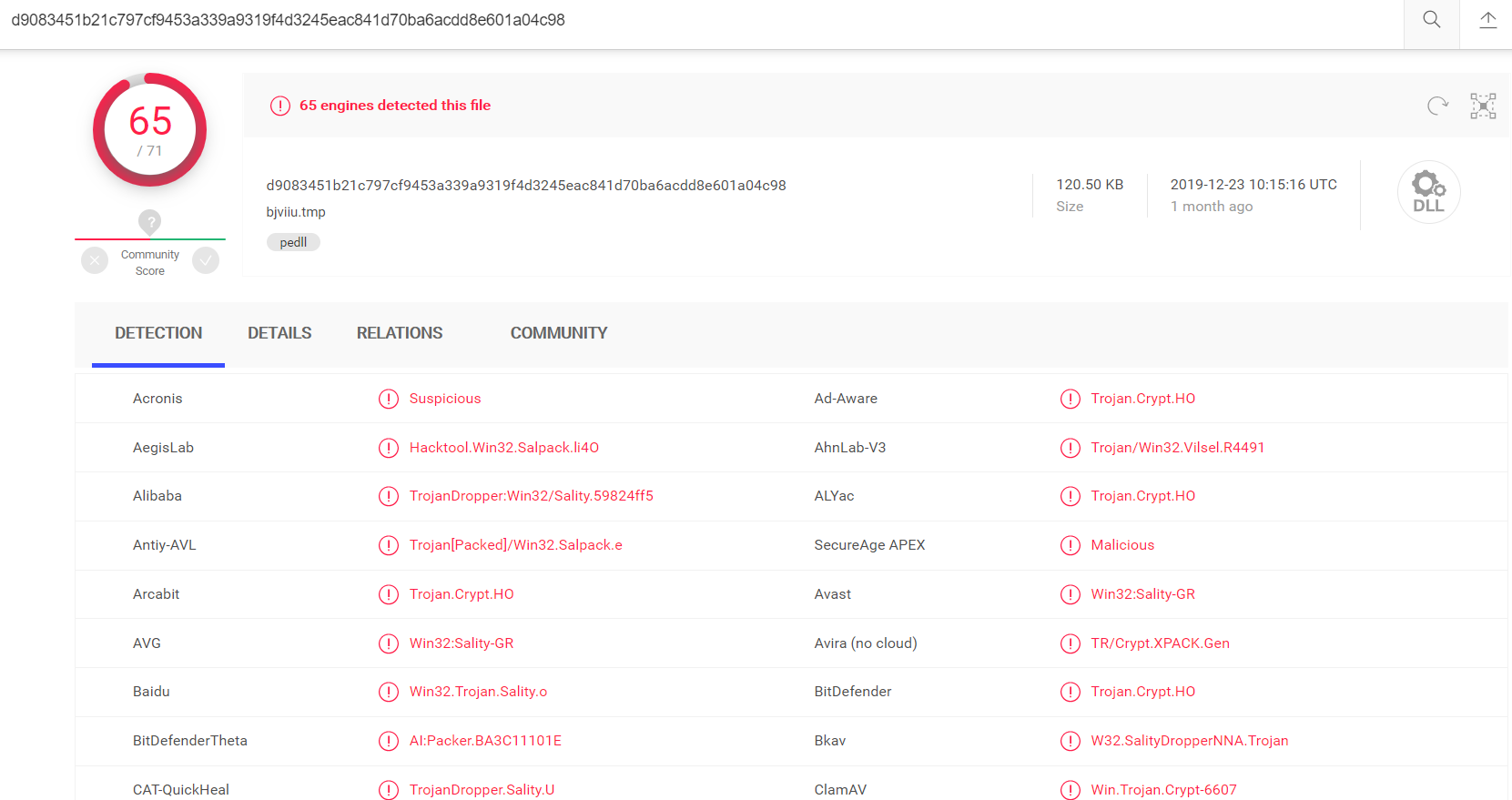
图 1-5 多引擎鉴定
除了使用多引擎技术查杀外,还可以使用 yara 类的文件特征匹配引擎来鉴定。
例如下面这个 Emotet 家族的 yara 规则
rule Emotets{
meta:
author = "pekeinfo"
date = "2017-10-18"
description = "Emotets"
strings:
$mz = { 4d 5a }
$cmovnz={ 0f 45 fb 0f 45 de }
$mov_esp_0={ C7 04 24 00 00 00 00 89 44 24 0? }
$_eax={ 89 E? 8D ?? 24 ?? 89 ?? FF D0 83 EC 04 }
condition:
($mz at 0 and $_eax in( 0x2854..0x4000)) and ($cmovnz or $mov_esp_0)
}
通过对样本的逆向分析找出关键代码,可以编写出匹配 PE 文件特定偏移中出现的机器码的 yara 规则。
除了专家规则,通过积累的大量恶意样本和总结的专家经验,可以选择出合适的机器学习算法来训练有效的查杀模型。例如360的 QVM。
VT 上也有很多厂商在判断新样本的时候会给出一个含有百分比的标签,这种也是算法给出的一个判断,但是这一类的算法有个问题是只能判断黑白灰的概率,无法给出准确的家族鉴定。
动态鉴定
动态样本鉴定一般使用沙箱技术,比较出名的开源沙箱如 Cuckoo,会在虚拟机中将样本运行起来,记录下样本运行时的各类系统调用和关键行为,并提取读写注册表、创建互斥体、创建释放文件、启动子进程、send、connect 外部地址等等关键行为,以及重点标注出虚拟机检测、自定义时间计算对抗虚拟机加速执行等恶意程序常用的方法。
例如 habo 上的样本 order.docx
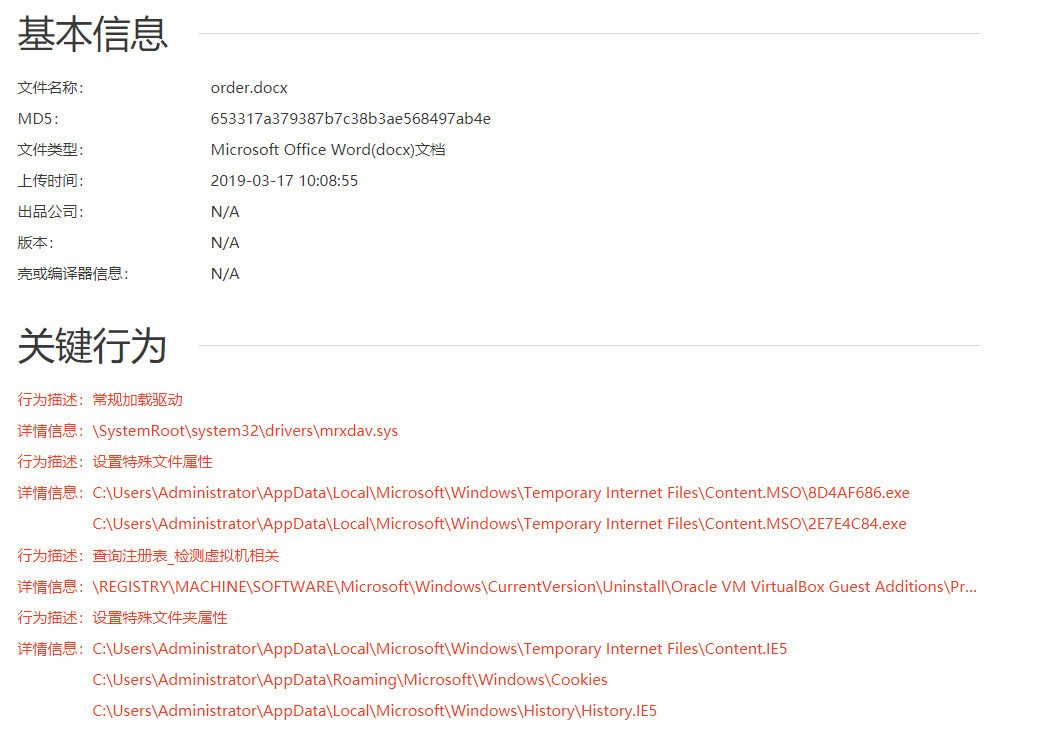
图 1-6 沙箱结果示例
标记出关键恶意行为只能判断样本是否恶意,或者得出基本的打分。要得到样本的家族分类,还需要有专家规则来做专门的鉴定,如 Cuckoo 有专门的 Signature 仓库 https://github.com/cuckoosandbox/community/tree/master/modules/signatures/windows。
上面贴过了鉴定 Emotet 家族的 yara 规则,其使用的是文件中的字节码特征来鉴定。而 Cuckoo 沙箱也支持规则编写,动态鉴定时使用的则是进程 API 调用序列,Mutex名、注册表读写、网络请求等等特征。例如下面的 Emotet Cuckoo Signature:
from lib.cuckoo.common.abstracts import Signature
class Emotet(Signature):
name = "trojan_emotet"
description = "Emotet Trojan Indicators Found"
severity = 3
categories = ["trojan"]
families = ["emotet"]
authors = ["RedSocks"]
minimum = "2.0"
mutexes_re = [
".*ci58c",
".*cm58c",
".*ci1a0",
".*rm974aade0",
]
regkeys_re = [
".*974aade0",
]
files_re = [
".*\\\\rqvkbvgl.exe",
]
def on_complete(self):
for indicator in self.mutexes_re:
mutex = self.check_mutex(pattern=indicator, regex=True)
if mutex:
self.mark_ioc("mutex", mutex)
for indicator in self.regkeys_re:
regkey = self.check_key(pattern=indicator, regex=True)
if regkey:
self.mark_ioc("registry", regkey)
for indicator in self.files_re:
regkey = self.check_file(pattern=indicator, regex=True)
if regkey:
self.mark_ioc("file", regkey)
return self.has_marks()
使用沙箱进行动态样本鉴定除了判断恶意和鉴定家族外,最重要的是提取样本的网络信息,以便后续通过数据处理实现 C2 的自动识别。要将情报的层次从样本级别提升到域名、ip 等基础设施这样更不易变的级别比较依赖动态数据,毕竟不是所有恶意程序都会傻乎乎的将c2地址直接硬编码到代码中。
沙箱虽然在威胁情报业务中十分重要,但是也存在集群部署成本高,研发和对抗困难等问题。除了收集样本到云端再在沙箱中运行,通过杀软、HIDS、EDR等产品采集数据也可以还原出部分关键数据,例如记录进程进行的网络请求、和敏感操作等。虽然没有 API 调用的完整序列,但是有了这些关键数据,并且数据量比自建的沙箱集群大很多,便可以进行后续的大数据分析了。
家族分类
从上面的图 1-1 可以看出,样本的 hash 是最容易发生变化的数据,比如病毒样本文件随便添加几个字节即可导致其 hash 值发生变化。要得到有价值的信息除了刚才说到过的从行为日志中提取网络行为外,对样本家族进行分类也是十分重要的一点。
恶意程序也是由黑产从业人员或者团伙开发的软件,根据其功能大致分为有僵尸网络(bot net)、木马、蠕虫、病毒四种,其他还包括勒索软件和流氓软件等等。既然是软件就有不同的名字,虽然恶意软件作者不会自己给出名字,但是杀毒软件厂商会对其取名,并将同一种恶意软件的不同版本(变种)通过静态、动态查杀手段鉴定出来,归于一类。
例如 Emotet 银行木马家族在卡巴斯基上的病毒名为 Trojan-Banker.Win32.Emotet,说明了它是一个在 Windows 平台上运行的木马家族,家族名为 Emotet,就算其代码有部分更新,或者是样本 hash 发生了变化,杀毒软件鉴定成功后报毒时依然会叫 Emotet。
黑产人员开发恶意软件通常有其特殊的目的,如僵尸网络类的恶意软件会感染控制很多肉鸡组成僵尸网络,然后根据需要发起DDos攻击或者下发挖矿指令。而勒索软件则是会加密受感染电脑上的文件然后向用户索要赎金。家族分类就是为了将每种恶意软件的主要类型,攻击目标,以及使用的手法和手动查杀的方法积累下来。
比如微软给出的 Rammit 家族的信息
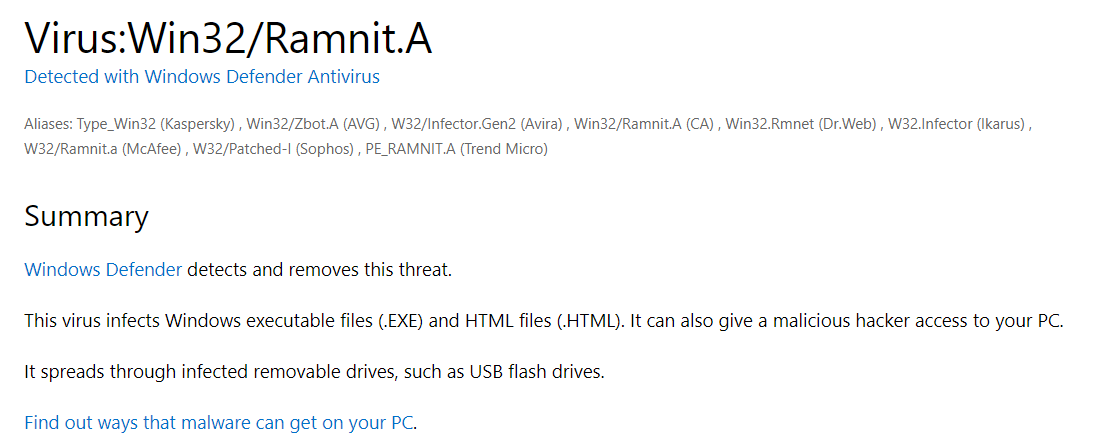
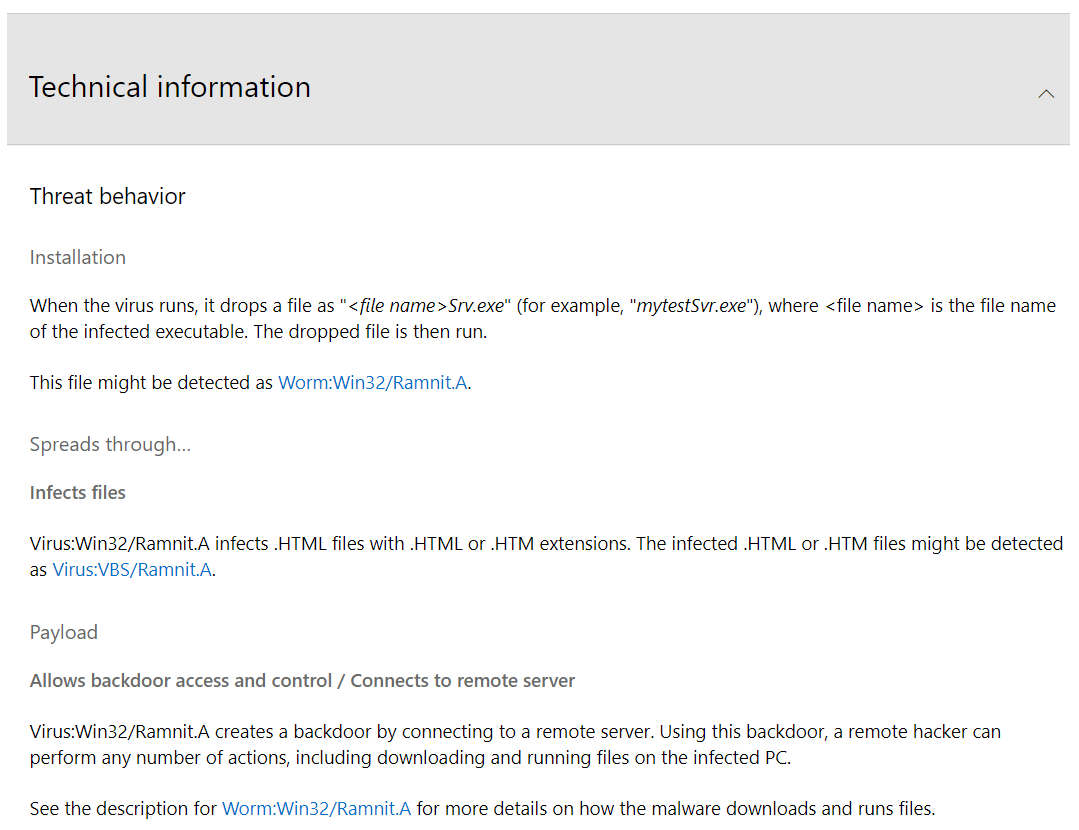
图 1-7 家族信息示例
基础设施信息
在图1-1的痛苦金字塔中,文件样本 HASH 的上一层为主机特征和网络特征。其中主机特征为互斥体、运行路径、注册表项等沙箱动态鉴定器所使用的特征,大多需要安全专家人工分析总结得出。而网络特征中包括,IP、域名、URL 和通信协议,其中通信协议和主机特征一样,需要人工分析得出,可以编写为 IDS 规则,配合沙箱或者在网络流量中用于直接发现恶意软件的通信,但始终难以自动化得出。剩余的 IP、域名和 URL(URL中包含 ip 或者域名) 即为所谓的基础设施信息。
基础设施是黑产人员的资产,相比样本 HASH 获取难度更高,但其稳定性能强,因为黑产人员要得到基础设施必须付出现实成本,通常也就是需要花钱购买,每一个 IP 背后都可能是一台主机(通常为云主机),而域名也需要花费金钱购买。
而购买和使用基础设施必然会留下一些痕迹,通过这些痕迹便可以分析出更高维度的组织等信息,或者是通过这些痕迹将基础设施关联起来。例如说切换了域名但是都指向同一个 ip,或者是使用同一个个邮箱注册了多个域名。
威胁情报对外输出的内容最主要便是IOC,并且大多是域名和IP等基础设施信息。IOC(Indicator of compromise) 即失陷检测指标,是威胁情报中最方便使用并且有效的数据。而根据其功能大致分为 C2 和传播源两种,如果在网络请求中检测到了 C2 访问,便基本可以判定内网中有主机被攻陷,这时再辅以端上采集的进程网络信息,排除浏览器等进程即可确认失陷。并且 C2 关联上恶意软件的类型和家族即可确认感染的是哪一种恶意软件,可能有什么危害,并确认清除方案和指导后续提升安全防护的措施。
说了半天基础设施信息的重要性,那么在威胁情报生产中基础设施究竟如何得到呢。
参考图 1-0 数据生产的流程。基础设施数据生产也是从样本出发,收集尽量多维度的信息,提取关系和属性,结构化存储后再进行数据处理后得到结果。只是和样本维度相比,要做基础设施生产需要收集的信息维度要多很多。存储所需要的大数据组件也更多样,处理的复杂性会高上很多倍。具体步骤如下图所示
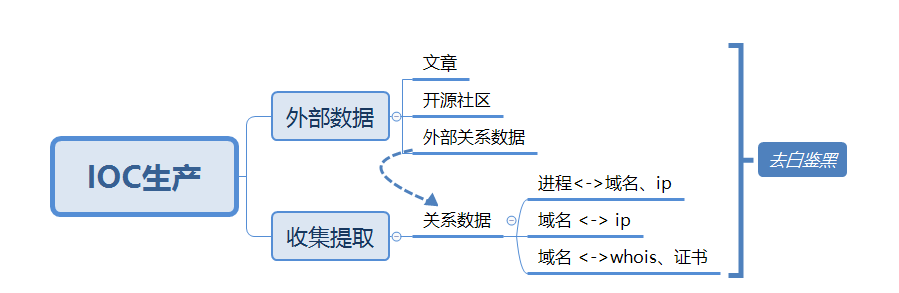
图 2-1 IOC生产流程
首先要确定的就是要提取哪些关系和收集什么数据,这需要先梳理、观察数据,然后总结出来,结论可以直接参考 VT 上域名 0-day.us 的关系图:https://www.virustotal.com/gui/domain/0-day.us/relations
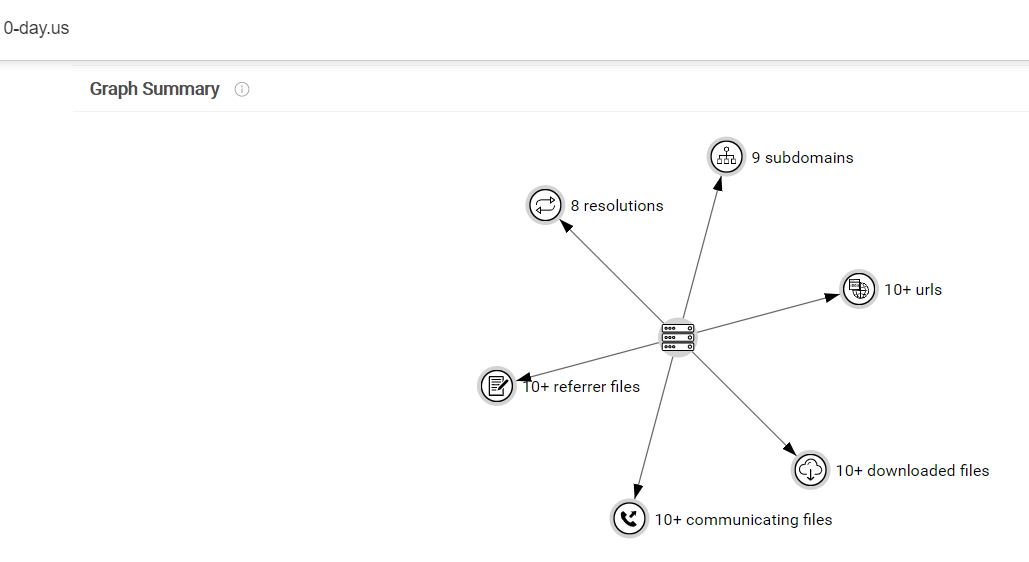
图 2-2 VT关系示例
可以看到 VT 的 Graph 中列举了:
- 域名的历史解析ip(dns、pdns 数据)
- 子域名信息(dns分析可得出)
- 域名下的 url 信息(从样本的网络行为中提取)
- 和域名通信的样本信息(从样本的网络行为中提取)
- 从域名下载的样本信息(也是从网络行为中提取)
- 文件中包含域名信息的样本(静态样本鉴定时得到)
在其他界面上还列举了:
- 域名的历史 whois 信息(域名是有时限的,到期可能不会续费或被他人购买)
- 域名的历史证书信息(证书同理)
除了上面的关系外,还需要有域名的 alexa 排名,多引擎判断结果(是否为钓鱼网站等恶意网站)等相关属性。
IP维度以及样本的关系和属性可以以此内推,因为太多太复杂就不一一列举了。这些关系和属性也是在日常和黑产的攻防对抗中逐渐总结出来的,上面已经提到过一些总结的逻辑了,这里也不再展开。
接下来我们从技术角度出发,讲一下如何存储并利用这些数据,建立完整的数据生产 pipeline。
这里想推荐一本书给大家,书名叫《Designing Data-Intensive Applications》。因为接下来会介绍相当多的大数据组件,这本书从全局的角度比较清晰的讲述了常见的大数据组件适合的存储与计算场景。
数据存储
以上面的域名 0-day.us 为例,其数据来源不止一处,可能有非结构化的文本类数据,也有已经结构化存储到 db 的数据。数据的更新频率和需要存储的时间也各不相同。有些数据可以直接得到,而有些需要再次加工。
比如沙箱所产生的样本对应网络关系可能可以直接生成到 DB 中,而证书和 whois 信息等则可能是文本格式,并且需要数据处理才能提取出其中的域名和注册人等然后才能格式化存储。像IP对应的端口这类数据可能会快速变化需要ES等能快速检索按天更新的,而whois信息则变化相对较慢,可以存到 Hive 中,并将原始文本存储在 HDFS 或 Ceph 的对象存储系统中。而像域名这类有排名和类型判断等属性的数据可以存放在 Hbase 这类列存储中。
而最关键的则是存储域名、ip、样本之前关系所需要用到的图数据库。因为传统的类似 MySQL 的数据库要存储关系只能将像域名映射 ip 这样的一个映射(也就是一条边)存储在一张表中,如果想要得到样本访问的域名对应的ip的话则需要 join 两张表,而通常关系处理都需要遍历多条边,使用传统数据库的话 SQL 调用会十分复杂性能消耗也会非常大,不利于使用。图数据库就是基本这种场景开发。常见的图数据库有下面几种:
| 名称 | 存储引擎 | 支持计算 | 支持分布式 | 复杂性 |
|---|---|---|---|---|
| neo4j | 自带 | 自带 | 需付费 | 低 |
| JanusGraph | HBase、BigTable 等等 | Spark、Hadoop | 基于 Hadoop | 高 |
| Haddop S2graph | HBase | 否 | 是 | 高 |
其中 neo4j 适合本地调试研究。S2graph 基于 HBase,适合大规模的图存储和知识图谱上的推理。而 JanusGraph 背后有 Google 支持,功能最丰富,除了支持知识推理外还支持图计算,如社群发现等。总结下来 JanusGraph 可能更合适使用,但是笔者在工作中对 S2graph 接触比较多,所以下面的图数据库都以 S2graph 为例。完整的数据存储流程图如下:
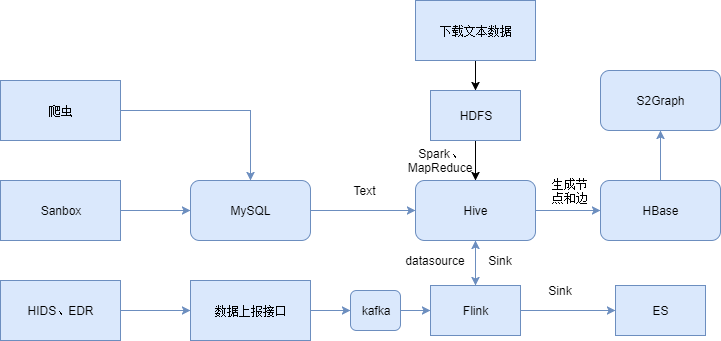
图 2-3 数据存储流程图
各个来源的数据,经过 ETL 和各种处理逻辑后统一汇总到 Hive 进行长期存储,然后再按天或者小时导入到 HBase 中。S2graph 底层使用 HBase 存储节点属性和边的数据,其他的 meta data 和 Hive 一样是存储在 DB 中的。数据按照 DB 中设置的节点属性和边的属性写入到 HBase 对应的表中即可在 S2Graph 使用 http api 进行关系查询。
数据处理
数据收集上来之后,还需要经过处理才能够最终使用。
例如 DB 中的沙箱 API 调用日志中,需要遍历提取关键的 API,如 CONNECT 和 SEND 调用。从 DB 中读取该行调用,获取到对应的进程 md5 和 域名、ip 后写入 Hive 中。再按格式整理写入 HBase 才能在 HBase 中使用。
首先从在 Python 或者 Java 中读取 db 中沙箱已知恶意软件运行产生的数据。
maleware_name = "rammit"
md5s = db.exec('select md5 from malware_samples where name like"%rammit%"')
for md5 in md5s:
param1 = db.exec('select param1 from sandbox_apis_{date} where api_name="connect" and md5={md5}')
if is_domain(param1):
db.exec('insert into md5_visit_domain (md5,domain) values('%md5','%domain')', md5, domain)
然后需要从 db 导入到 Hive, 这一步一般由大数据任务平台实现,例如开源的 Apache Oozie,Google 的 Google Cloud Dataflow,腾讯和阿里也有自己对应的实现(阿里的 ODPS 和腾讯的数据工厂)。
这些平台中可以创建 Hive、MapReduce 或 Spark 任务,然后给这些任务设置依赖关系,并设置定时调度。比如这里需要先建一个任务从沙箱结果的 MySql 表中导入到 Hive 临时表,再建一个任务依赖之前的任务并执行 Hive 语句写入结果表,最后在平台中到出到 HBase 中。
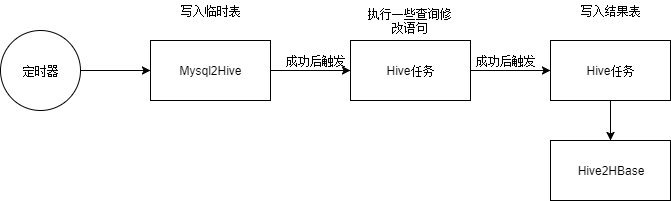
图 2-4 大数据平台任务示例
这一部分的数据处理主要涉及到 Hive 语句的使用,和使用 Java 开发特定的 Hive UDF 函数并上传到平台中在 Hive 里调用。平台中一般还会有资源管理、失败重试等等各类功能来保证业务的使用便捷性。像域名的热度数据也需要在 Hive 中根据 DNS 查询的数量在 Hive 中统计得出。更多具体 DB 和 Hive 的使用可以参考博客中数据分析的七种武器-sql和数据分析的七种武器-hive 等文章。
上面提到的属于批处理式任务,除此之外在一些时间要求比较严格的地方还需要使用实时计算技术,目前最火热的实时计算框架为 Apache Flink(这里也可以参考数据分析的七种武器-flink了解更多使用方式),在威胁情报生成业务中,像一些特征较为明显的家族可以从网络访问中直接匹配特征发现其 C2,这样可以最快的产生有效的情报。
如VT上的这个 Sality 样本,从 Relation 界面可以看到其访问的 URL 为 http://padrup.com/sobaka1.gif?44f62=1129864,在统计大量的 Sality 样本后可以发现,其 URL 都满足 \w+\.gif\?\d+=\d+ 这样一个正则格式,于是可以开发一个 Flink 任务匹配所有从 HIDS、EDR 上上报的网络流量,捞出满足该格式的 URL 并提取出其中的域名然后写入疑似恶意的域名库中。
在 Flink 中先将上报数据写入的 Kafka Topic 注册为 datasource,然后再将其注册为 table,比如叫 md5_vist_url。并创建 datastream 接受输出并sink到Hive,同时注册为 Flink table 名为 suspected_domains,然后编写 Flink SQL 语句如下:
Insert INTO suspected_domains
SELECT extract_domain(url) AS domain, "sality" FROM md5_vist_url WHERE regex('\w+\.gif\?\d+=\d+', url)
//其中 extract_domain 为 java 编写上传到 Flink 平台的 UDF。
使用实时计算技术实现一个规则引擎,再结合 ATT&CK 中总结的一些攻击手法还可以从 HIDS、EDR 上报的进程关系链中发现杀软无法发现的未知威胁(使用0day、nday,白加黑,无文件攻击等等)。例如最简单的发现一个 WORD.exe 拉起了以恶 CMD.exe 然后发起了网络请求,再比如提取 ATT&CK 持久化常用的手法中常用的 bitsjob–[BITSAdmin] (https://attack.mitre.org/techniques/T1197/)命令理写入的域名、ip,著名的 APT 攻击套件 Cobalt Strike 中就使用了该工具。仔细整理 ATT&CK 手法再编写对应规则可以发现很多隐藏比较深的攻击,甚至可以抓到一些 0day,因为这个话题太大这里也不再继续展开。
说完了批处理部分和实时计算部分,情报生产的重头戏还是在知识图谱也就是 S2Graph 图数据库上。
所谓的知识图谱是由 Google 提出的一种用图这种形式存储知识的数据库,图由节点(实体)、属性和边组成。例如 王小明今年13岁,他的爸爸叫王大明。这里描述的知识在图中可以表示为 两个节点,王小明和王大明,王小明节点有属性为年龄值为13。然后有一条边,由王小明指向王大明,边的名称为父亲代表大明是小明的父亲。如果这时再由王大明指向一个新的节点叫王老明,想在图中查找王小明的爷爷便可以从王小明节点往上遍历两条边得到。图如下:
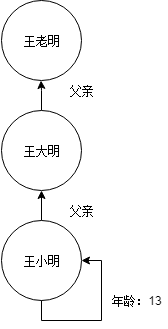
图 2-5 知识图谱示例
这里举例寻找王小明爷爷的场景在知识图谱中叫做知识推理,知识图谱技术在搜索、推荐和风控等等领域都有许多应用,有时间的话可以阅读一下机器之心的这篇文章做更多了解 https://www.jiqizhixin.com/articles/2018-06-20-4。
上面介绍威胁情报的基础设施信息(域名、ip)的时候已经介绍过 VT 上的图数据都有哪些节点和关系,如上面举例的 0-day.us 域名,在 VT 的图分析界面中展示如下:
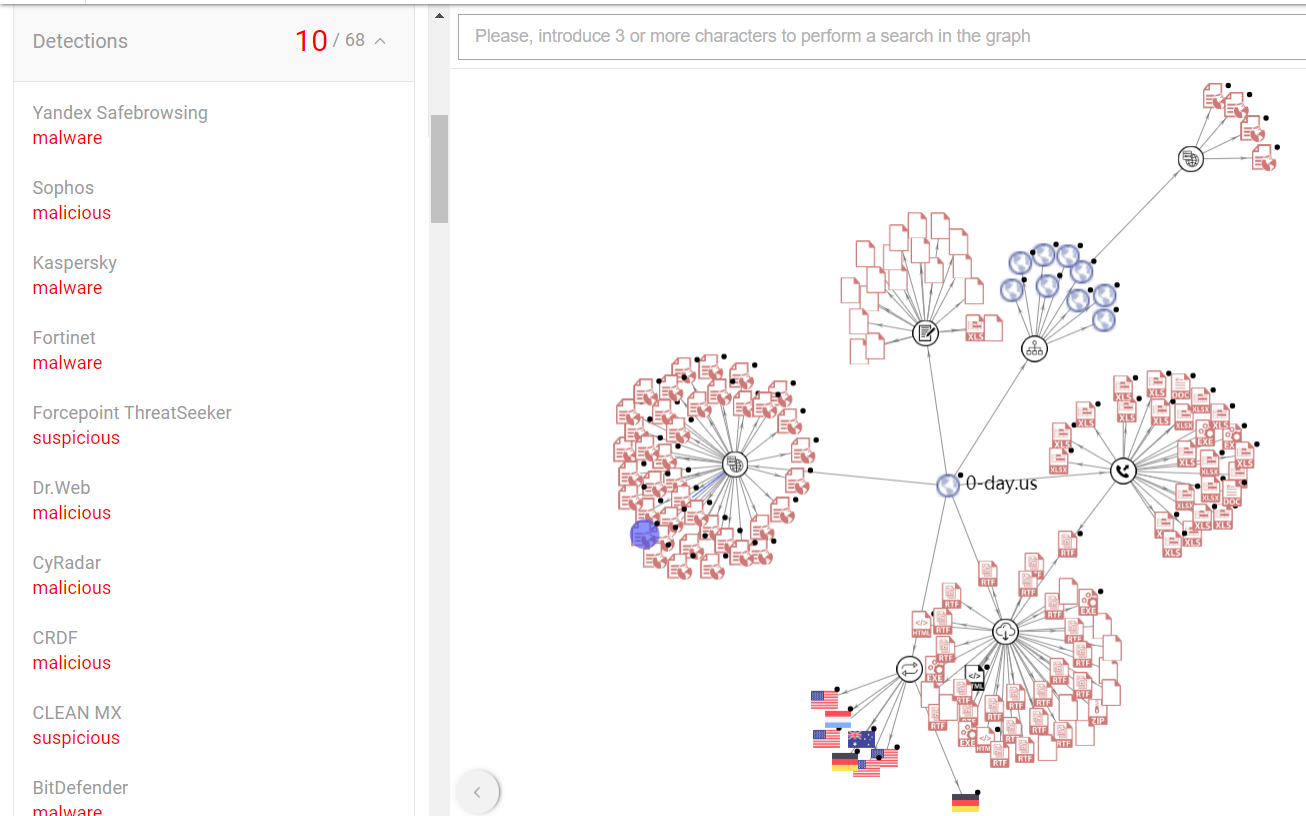
图 2-6 情报图谱示例
可以看到 0-day.us 连接的其他节点可以继续展开,也就是说在知识图谱中我们可以做多级关系的遍历,并且这种遍历也可以是双向的。然后一个域名可以有很多关联的访问该域名的程序,并且从域名出发可以列举出所有访问的程序,点击每个程序还可以获取其属性值(是否恶意等)。
基于图谱的以上三点特征我们可以总结出一条很简单的规则,即被大量相同恶意类型、不同 md5 样本访问的一个域名很有可能是某家族的 c2 域名。
在 S2Graph 中,提供了图查询的 http 接口,通过该接口我们可以实现上述的规则。该接口中需要指定开始的节点名即 srcVertices 以及索引到特定节点的值即id,然后指定要遍历的每条边,即 steps 中的 Json Object,其中 label 是边的名称,direction 是方向。因为 S2graph 的特殊设计,节点的属性也是一条边,不过是一条从节点出发指向节点本身的边。编写规则如下:
curl -XPOST http://s2graph.localhost/queryedges -H 'Content-Type: Application/json' -d '
{
"srcVertices": [{"serviceName": "column","columnName": "domain","id": "0-day.us"}],
"steps":[
{
"step": [{"label": "md5_visit_domain","direction": "in","offset": 0,"limit": 10,"duplicate": "raw"}]
},
{
"step": [{"label": "md5_self_prop", "direction": "out","offset": 0,"limit": 10,"duplicate": "raw","where":"detection=malware"}]
}
]
}'
图谱中实体、属性和边的数据收集写入的过程在数据存储部分已经提到,该过程在知识图谱的概念中中叫出知识抽取,通过知识抽取我们可以搭建出完整的知识图谱。总结出各类规则对其中的数据进行利用。图谱中的节点和关系越多我们的规则会越接近真实,例如上面的这条规则,如果只有单一样本的数据,便只能使用传统的基于特征的规则。而在有了大量数据的情况下,知识图谱的推理计算能力便能发挥威力,能够自动化的发现很多以前光靠人工无法发现或者处理不过来的数据。
既然知识图谱也是图,那么除了知识推理外,其他的图算法也可以应用在知识图谱上。
比如社区发现算法算法,该算法目的是在图中找到聚集的一堆节点。因为同一家族的恶意软件可能感染同过一批机器或者使用过相同的 ip 做 c2,天生就会具有聚集性,使用社区发现算法可以找出一批疑似恶意的域名。比较常用的社区发现算法有 Minimum-cut method、Girvan–Newman algorithm等等。
从样本层面到基础设施层面,从人工分析到利用大数据和算法实现自动化,其实攻防的本质还是技术对抗。在人力有限的情况下使用更高层次和更自动化的手法才能和由利益驱动不断更新技术栈的黑产相对抗。在威胁情报产品中是这样,在其他安全产品里也是一样。
运营
文章开头的时候提到过,乙方商业威胁情报厂商和普通的开源情报对比最明显的区别就是有没有运营环节,这里所说的运营包括人工运营和自动化运营。人工运营可以看作是最原始的恶意样本人工分析工作的延续,大多数安全产品在开发完善后都会进入一个长期的运营环节,因为所有安全产品最终的目的都是要发现真正的安全问题。就像威胁情报生产环节中发现的大多数恶意域名和 ip 其实都属于疑似恶意,到真正确认恶意并能对外使用还有很多步骤要走。
从海量的 ip、域名中发现真正的 c2 就和在网络流量中发现攻击类似,发现异常容易,但是要精准的发现攻击是一件很难的事情,毕竟攻击在整个流量中来看是一个小概率事件。恶意的 c2 在海量的ip、域名中也是属于极少数。因此,对 IOC 的质量可以有一个很简单的评价标准,如果使用某个 IOC 库在公司网络中一天的报警超过了 100 个,那么就和没有是一样的了,在大量误报中找到真正的报警是很难做到的。
威胁情报的运营和 WAF 等安全产品的运营也类似,首先就是建立自动化的数据漏斗,过滤大部分无用的数据。在这一步中,最普遍的就是建立黑白名单。
白名单
在以往威胁情报告警运营中,最令人尴尬的误报就是像 baidu.com github.com 等域名出现在了告警之中。如果商业版的威胁情报出现这一类的域名,不仅会让客户觉得产品不靠谱,甚至有可能导致订单被其他友商抢走。在甲方工作的过程中也见到过在做 dns 隧道检测和 DGA 域名预测时,告警中有不少 aliyun.com 之类云厂商 api 地址和一些内网域名或 ip,出现这种情况说明在工作时还不够谨慎。
所以威胁情报运营的第一步就是建立好白名单库,并且在不断的告警运营中将误报的 ip、域名补充到白名单中。像域名白名单可以下载 Alexa 排名前 10w 的域名或者再辅助以 dns 数据计算热度来产生。其他的 cdn 域名等也是常见误报来源。
而 ip 类的白名单则稍微会麻烦一些,并且 ip 类 c2 的失效速度会比域名快上许多。像小区宽带 ip 这一类需要购买外部数据,国内 ipip.net 有该数据售卖。而运营商骨干网 ip 等可以从 ASN 信息中得到,censys.io 等网站可以爬取一部分。最简单的内网 ip 需要首先排除,因为威胁情报给出的 IOC 是属于可以分享的互联网上的资产信息,内网攻击不在威胁情报 IOC 的覆盖范围内。甲方的运营分析人员使用威胁情报时,首先可以将内网的域名和ip加入到白名单中过滤。
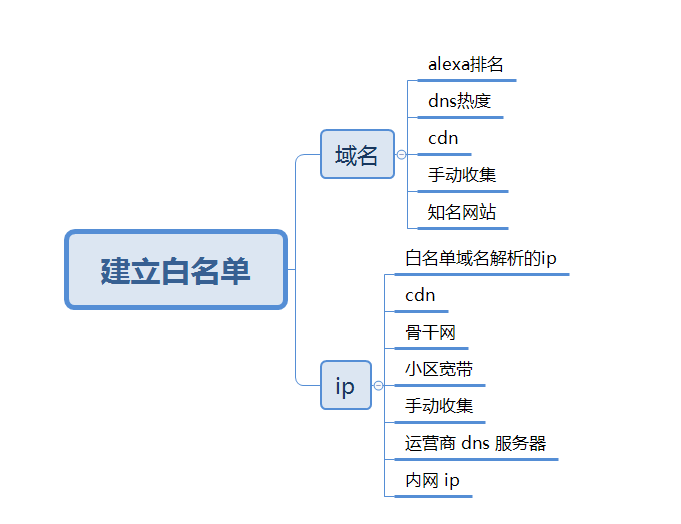
图 2-7 白名单建立
白名单数据的数量一般不会太多,收集好白名单数据后可以存储在 MySQL 等 db 中,然后开发一个简单的管理系统来给其添加标签和删除错误数据等,并且该数据可以在多个安全产品间共享。
黑名单
在 WAF 等安全产品中,会将攻击过的 ip 或者直接将所以云服务器的 ip 直接拦截,而威胁情报对外的形式也是类似一个黑名单库。不过有一些恶意的域名和 ip 不需要通过很长的流程即可生产。
第一类就是 Sinkhole ip 和 Sinkhole 域名,DNS Sinkhole 是安全厂商对抗恶意软件的一种方式,即联系域名注册商将恶意软件使用的域名接管,解析到自己用于接管的 ip。所以内网中发现有连接到这些 Sinkhole ip 的请求多半已经被感染,Sinhole ip 可以直接用作 IOC,而解析到这些 ip 的域名同理。常见的 Sinkhole IP 列表可以参考这个 Github 仓库 https://github.com/brakmic/Sinkholes。
第二类就是矿池的域名、ip 和 tor 节点 ip,通常在企业内网或者服务器上发现有连接矿池的请求时有很大几率是感染了挖矿木马或者是有员工违规利用公司资源在挖矿。国外有专门的网站收集 tor 节点信息,如 https://www.dan.me.uk/tornodes。更进一步可以爬取暗网中文交易论坛中的交易贴,分析隐私信息售卖的情况来监控企业是否发生了数据泄露。
第三类则是 DGA 域名,DGA 全称 Domain Generation Algorithm 是恶意软件开发用于对抗情报类检测的功能,即在恶意软件内植入一个生成域名的算法,根据时间每天生成多个不同的域名,然后每天在注册其中某一个域名即可实现对感染机器的控制。在逆向恶意样本后安全分析人员可以还原出每个样本使用的 DGA 算法,在 Github 上有分安全分析人员共享了一些已经家族的 DGA 算法 https://github.com/pchaigno/dga-collection,每天运行仓库中的脚本即可得到这些家族当天使用的 DGA 域名并检测。另外也有可以直接订阅 DGA 域名的网站 https://dgarchive.caad.fkie.fraunhofer.de/welcome/。除此之外,还可以使用熵值计算或者用已知家族的历史 DGA 域名通过深度学习算法(LSTM等)来预测。
还有就是上面提到过的分析文章中附带的 IOC 数据,这类数据可以人工阅读文章后通过运营系统添加到情报库,也可以通过 NLP 技术在爬取文章原文后自动标注。
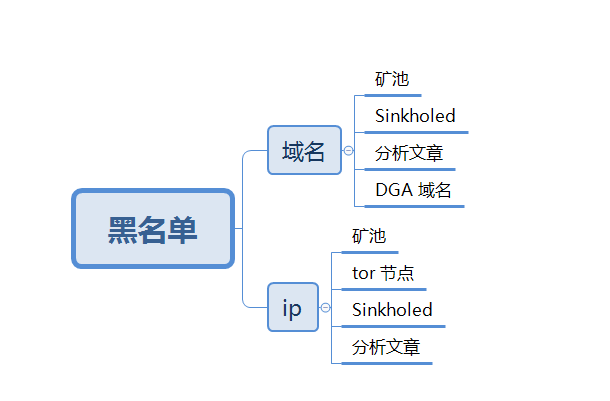
图 2-8 黑名单
甲方安全团队在没有充足的经费购买商业情报库的情况下,可以参考黑白名单运营流程加上可信度高的开源情报库自建情报库。
标签和TTP信息
在图 2-1 IOC生产流程中提到过,利用大数据生产威胁情报最主要的步骤叫做去白鉴黑。前期各种规则和算法都是在过滤出疑似的 IOC,而真正要对外输出的 IOC 需要是高可信的运营级 IOC。运营级是经过严格审核的可以用于生产环境边界或终端匹配拦截的 IOC,运营级需要有背景信息、威胁等级、处置建议等信息。例如下图的驱动人生木马团伙 IOC:

图 2-9 驱动人生木马团伙
在运营出白名单和黑名单后,可以自动化将疑似的 IOC 信息进行第一道过滤。而后还需要进行人工确认。并且通过一些自动化的手法给出标签和家族信息,再以标签、家族信息作索引来给予不同的风险等级和处置建议。简单来说如果某 IOC 在图谱中只被某一个样本家族访问而没有浏览器等白进程访问的化,那么可以将该样本的家族标签赋与该 IOC。而处置修复建议也和上文中提到的样本家族分类信息类似,只是在除了指导在终端上如何移除恶意程序外,还会有配置防火墙规则,或在域控中下发类似关闭 139、445端口服务等建议。
在积累了大量黑白样本后,即可使用 BOOST、决策树等算法从图谱中抽取各个维度的特征来训练出自动去白鉴黑的模型。
告警运营
得到了运营级的情报库后,威胁情报的还需要有使用的载体,如 HIDS、SOC、NIDS、EDR 等。其中和 IOC 结合最好的还是 HIDS 和 EDR 类产品,因为它门可以收集端上的进程网络行为数据,这样告警的误报率最小,也方便后续的回溯分析。
在之前的工作中,除了生产威胁情报外还要运营公司各类安全产品中情报的告警,这些数据也是威胁情报生产的一个重要补充部分。当情报的准备率达到一个相对稳定的值后,告警数量不会太多,例如安全防护做的很不错的腾讯来说,每天新增的不重复告警不会超过 100 条。再加上帮客户运营告警数据后,人工分析每一个告警即可将可能会触发误报的 IOC 及时删除。比如在多个客户处发现 IOC 告警对应的进程基本是浏览器或 SVCHOST DNS 宿主进程的话该 IOC 基本可以判断是误报。
在告警运营过程中还可以将感染量大,但是出自一些自动化流程,标签和家族不明的 IOC 收集起来进行人工分析,很可能会发现一些新的家族类型。在这之后还能继续收集他们的 TTP 信息,再进一步整理其团伙信息。在某些情况下还可以定位到黑产团伙的具体人员信息,上报公安部分实施抓捕。
总结
本文通过介绍乙方商业威胁情报厂商的生产运营流程,对如何通过大数据发现威胁情报的技术细节和公开的数据来源进行了简单的介绍。
接下来还有:
《威胁情报系列(三):威胁情报怎么用》
敬请期待。
参考阅读
- 《恶意代码分析实战》
- 《Designing Data-Intensive Applications》
- 《知识图谱技术与应用指南》– https://www.jiqizhixin.com/articles/2018-06-20-4
- https://blogs.akamai.com/2018/01/a-death-match-of-domain-generation-algorithms.html