数据分析的七种武器-flink
Flink 是一个开源分布式流式处理引擎,支持将数据分发到多个节点,并提供容错机制(fault tolerance),可以分布式的对流式数据进行处理。
Steaming Processing
所谓的流处理是 Steaming Processing 的翻译,相对于基于 Haddop 的批处理(Batch Processing),流式处理对应的数据是没有开始结束一直产生的实时数据,就像是河里的水一样,所以翻译为流处理。
传统的批处理中,数据需要落地在存储(HDFS等)中,再通过 Hadoop MapReduce、Hive 或者 Spark 等方式进行处理。但是这种模型在一些特定场景不适用, 例如统计实时的用户行为数据来推荐广告,或者在安全或者业务中需要0延时的对数据进行实时的监控分析并告警, 以及一些数据分析场景需要将正在发生的事统计出报表用于展示。
流处理的发展由一开始的单机数据库+内存处理,到2000-2010年间的基于CEP 模型的商业软件(如IBM qradar, 以及开源的 esper )等,该阶段的流处理引擎的功能基本和今日类似,但没有解决错误容忍、横向扩容以及模型自定义等问题。
后来开源社区中出现了 Storm 和 Spark Streaming 等框架,后来有了 Flink(三者的对比可以参考medium上的这篇文章)。
其中 Spark Streaming 使用的是 Micro-batching,即将指定窗口大小的事件缓存,再利用批处理的逻辑去处理。这在实时性要求不那么高的统计等场景下比较适用,但是满足不了安全业务中对时间和事件的准确性要求。
Storm 是早期最流行的流处理框架,但是其不支持聚合、窗口等高级特性,而且也没有简单易用的 api 而是需要自己构建拓扑(2.0 版本支持 SQL),并且对流事件只能保证 at least once 即至少处理一次(不适应安全告警等场景)。
而 Flink 支持 SQL 并且可以方便的进行 UDF 开发,同时社区自带 CEP 库。
关于 Flink 的开发模型可以参考其文档。
以下的 Demo 项目代码均在 Github seven-weapons-of-data-analysis。
Flink
根据 Flink 文档 中的描述, Flink 将流式处理做了如下抽下抽象:

最底层是对流事件的状态化处理,在这之上为对有状态的事件通过统一的 API(DataSteam API)进行处理。 Table API 则是对 DataSteam API 进行封装,提供类 SQL 的 DSL ,最上层的 Flink SQL 则是可以脱离 Java、Scala 等语言,直接通过编写 SQL 进行流处理逻辑的开发。
DataStream Demo
根据教程,创建 demo project
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.8.0 \
-DgroupId=wiki-edits \
-DartifactId=wiki-edits \
-Dversion=0.1 \
-Dpackage=wikiedits \
-DinteractiveMode=false
其主要代码如下:
package wikiedits;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});
result.print();
see.execute();
}
}
WikipediaEditsSource 代码 中,继承了 flink 的 RichSourceFunction ,通过 IRC 爬取 wikipedia IRC 频道中的消息,处理为格式化的 Event(WikipediaEditEvent),推送到 DataStream 中。
public class WikipediaEditsSource extends RichSourceFunction<WikipediaEditEvent> {
....
@Override
public void run(SourceContext<WikipediaEditEvent> ctx) throws Exception {
try (WikipediaEditEventIrcStream ircStream = new WikipediaEditEventIrcStream(host, port)) {
// Open connection and join channel
ircStream.connect();
ircStream.join(channel);
try {
while (isRunning) {
// Query for the next edit event
WikipediaEditEvent edit = ircStream.getEdits().poll(100, TimeUnit.MILLISECONDS);
if (edit != null) {
ctx.collect(edit);
}
}
} finally {
ircStream.leave(channel);
}
}
}
}
主要的事件处理逻辑位于 WikipediaAnalysis 的 main 函数中,通过 KeySelector 选择 Event 中的 username 作为 groupby 的 key,KeyedStream。
在 KeyedStream 的基础上,开辟5s一个的时间窗口,并将相同用户的发言字节数相加。
在新的 flink-1.8 中 可以换成下面的写法,类似批处理中的 map reduce 写法可能更容易理解。
DataStream<WikiUserCount> result = edits
.map(new MapFunction<WikipediaEditEvent, WikiUserCount>() {
@Override
public WikiUserCount map(WikipediaEditEvent e) throws Exception {
return new WikiUserCount(e.getUser(), e.getByteDiff());
}
})
.keyBy("user")
.timeWindow(Time.seconds(5))
.reduce( new ReduceFunction<WikiUserCount>() {
@Override
public WikiUserCount reduce(WikiUserCount a, WikiUserCount b) {
return new WikiUserCount(a.user, a.count + b.count);
}
});
使用下面的命令编译、运行
mvn clean package
mvn exec:java -Dexec.mainClass=wikiedits.WikipediaAnalysis
输出的结果如下
2> Aaryangupta23 : -7
4> Wiki13565 : -6
4> Community Tech bot : 0
3> Joeykai : 35
1> EnterpriseyBot : -273
1> Db135 : -22
1> DeltaQuadBot : 414
1> DevGeekStar : 4
1> Joel David 99 : -111
1> Taumata994 : 1091
SQL Demo
根据文档, Flink SQL 和 Table API 都是将一个 DataSteam 即事件流抽象为 table 的概念,table 中的数据为一个个的事件,就类似数据库中的一条条数据。 通过 SQL 或者 DSL 对这些数据进行查询和分析。
使用 SQL 处理和上面一样的事件的核心代码如下(完整代码位于 Github seven-weapons-of-data-analysis):
首先需要初始化流处理环境,为了方便调试,可以使用 LocalEnvironment。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setParallelism(1);
然后需要初始化输入事件源的 Source Datastream,以及注册使用 SQL 需要的 TableEnvironment
DataStream<WikipediaEditEvent> edits = env.addSource(new WikipediaEditsSource());
StreamTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);
流式处理中有一个非常重要的数据即为每个事件的事件戳,Flink 需要事件的时间戳来处理基于时间窗口的统计。
Flink 中支持3种不同的时间戳: event time, processing time, and ingestion time。具体的区别可以参考其文档。
要使用事件时间来做处理,需要在环境中进行设置。
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
可以使用 Timestamp assigners 动态地给原来的 DataSteam 中的每个事件附上时间戳,并生成新的 Datasteam。
DataStream<WikiUserCount> dataset = edits
.map(new MapFunction<WikipediaEditEvent, WikiUserCount>() {
@Override
public WikiUserCount map(WikipediaEditEvent e) throws Exception {
return new WikiUserCount(e.getUser(), e.getByteDiff(), e.getTimestamp());
}
}).assignTimestampsAndWatermarks(extractor);
extractor 简单实现如下,直接返回事件中的 timestamp 字段。
private final static AscendingTimestampExtractor extractor = new AscendingTimestampExtractor<WikiUserCount>() {
@Override
public long extractAscendingTimestamp(WikiUserCount element) {
return element.timestamp;
}
};
进行了上面这些准备后,可以将 DataStream 注册为 table,将事件的字段绑定到表的字段上。然后就可以进行 SQL 查询了。
// Register it so we can use it in SQL
tableEnv.registerDataStream("sensors", dataset, "user, wordcount, timestamp, proctime.proctime");
String query = "SELECT user, SUM(wordcount) AS total, TUMBLE_END(proctime, INTERVAL '10' SECOND) FROM sensors GROUP BY TUMBLE(proctime, INTERVAL '10' SECOND), user";
Table table = tableEnv.sqlQuery(query); // https://flink.sojb.cn/dev/table/sql.html 1.7 中修改为 .sqlQuery
查询的结果为一个新的 table,可以将该 table 转换回 DataSteam 并打印
// convert to datastream https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/table/common.html#integration-with-datastream-and-dataset-api
TupleTypeInfo<Tuple3<String, Integer, Timestamp>> tupleType = new TupleTypeInfo<>(
Types.STRING(),
Types.INT(),
Types.SQL_TIMESTAMP());
DataStream<Tuple3<String, Integer, Timestamp>> dsTuple =
tableEnv.toAppendStream(table, tupleType);
dsTuple.print();
SQL 查询会转换为对应的执行计划,即 DAG 和具体的 DataStream 操作参考文档,可以使用 getExecutionPlan 得到执行计划的 json 表示,
将其提交到 flink visualizer 页面上即可查看可视化的执行计划。
System.out.println(env.getExecutionPlan());
该任务的 plan 如下
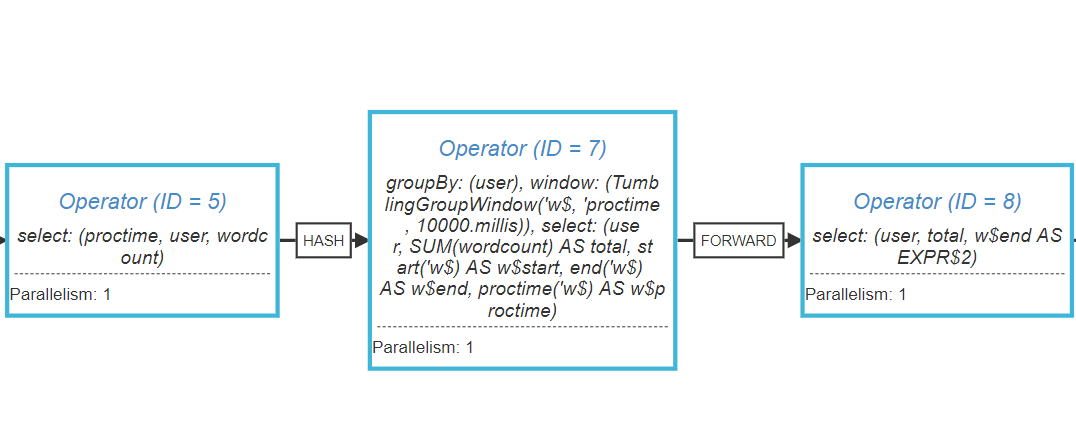
可以看到 plan 生成的结果和 DataSteam Demo 中的逻辑基本一致。
.keyBy("user")
.timeWindow(Time.seconds(5))
.reduce( new ReduceFunction<WikiUserCount>() {
@Override
public WikiUserCount reduce(WikiUserCount a, WikiUserCount b) {
return new WikiUserCount(a.user, a.count + b.count);
}
});
因为查询计划为惰性求值,当调用 execute 时才会被执行。
//stream.print();
env.execute("print job");
执行上述程序得到得结果如下:
(DudleyNY,94,2019-08-29 16:12:50.0)
(BrownHairedGirl,-5,2019-08-29 16:12:50.0)
(DemonDays64,1,2019-08-29 16:13:00.0)
(Ravensfire,818,2019-08-29 16:13:00.0)
(SJM2106,91,2019-08-29 16:13:10.0)
(TheSLEEVEmonkey,-37554,2019-08-29 16:13:10.0)
集群环境搭建
从 Dockerhub 拉取最新的 flink 镜像。
docker pull flink
然后编写 docker-compose.yml 如下:
version: "2.1"
services:
jobmanager:
image: ${FLINK_DOCKER_IMAGE_NAME:-flink}
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: ${FLINK_DOCKER_IMAGE_NAME:-flink}
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
使用 docker-compose 同时启动 jobmanager 和 taskmanager。
docker-compose up
服务暴露的端口如下:
The Web Client is on port 8081
JobManager RPC port 6123
TaskManagers RPC port 6122
TaskManagers Data port 6121
refs
https://medium.com/@mustafaakin/flink-streaming-sql-example-6076c1bc91c1 https://gist.github.com/mustafaakin/457859b8bf703c64029071c1139b593d