编译器开发从零单排(1)
前言
几年之前就想写一个系列的博客,记录一下从大学上完编译原理课后,不断尝试自己编写一个 C 语音编译器的过程。
在不断尝试的过程中,最大的感触有两个。
-
不要太高估自己的时间和精力,不要把目标定的太高。
做为互联网公司中的一线开发人员,在KPI的压力下,能够完成工作内容并学习一些工作相关的知识,已经很不容易了。只有在偶尔不加班的周末,或者下班以后十一二点到凌晨两点的安静的夜晚,才有时间分给写业余的出于爱好的代码,这也是工作之后写代码写的最开心的时间了。
-
参考成熟的大型的有广泛应用的项目代码(Clang, LLVM),先模仿学习。
结合理论阅读、调试代码,尝试把其每一步生成中间结果的步骤和逻辑分清楚。在此基础上选择自己熟悉的工具,设计好整个项目再分步实现。
这些尝试产生的结果即为 naivecompiler,一个由 Python、C++ 混合编写,基于 PLY 和 LLVM 的 C 语言子集编译器。
本来是打算先实现了计划中要支持的所有特性再开始写博客的,可是随着一年年的工作,发现要像国外的程序员抽出完整的时间做自己的 Side Project 是件过于奢侈的事,完成所有的特性遥遥无期。只能从长计议,边写代码边写博客,记录下学习过的理论知识、读源码的感悟、调试的心得,免得还没等到写完那一天就把这些都忘光了。
该项目主要参考 《编译原理》(龙书), pycparser, PLY 以及部分 GCC 和 Clang 的代码。
以及使用 Clang 的命令行参数,dump 出每一步的中间结果,用于参考。
典型编译器的结构
一个典型的静态语言编译器一般分为以下几个部分
- 词法分析 (Lexical analysis)
- 语法分析 (Syntax analysis)
- 语义分析 (Semantic analysis)
- 中间代码生成 (Intermediate representation code generation)
- 平台无关的代码优化 (Machine independent optimizations)
- 代码生成 (Code generation)
- 平台相关的代码优化 (Machine dependent optimizations)
- 目标文件的生成 (Object File generation)
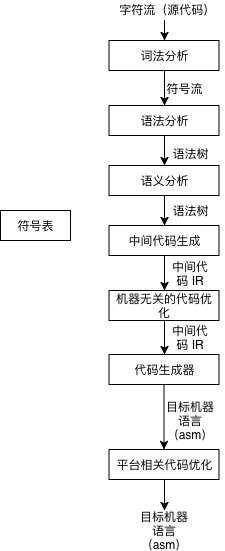
在此之外,将目标文件链接为可执行文件或者动态、静态链接库虽然是属于链接器的工作,但日常使用中我们一般也是通过编译器命令完成链接的过程,如 gcc hello.c -o hello ,该命令最终会生成一个名为 hello 的 ELF 可执行文件。
根据维基百科上 Compiler 的定义, 一个 Compiler 可以分为 3 部分,即 Front end、Middle end、Back end。
上面提到的 8 个步骤中,词法分析、语法分析、语义分析、中间代码生成属于 Front end,平台无关的代码优化属于 Middle end,代码生成、平台相关的代码优化、目标文件的生成则属于 Back end。
在 Clang 中,大致的编译流程为经过词法、语法分析后生成 AST。然后基于 AST 生成 CFG 进行各类 Analysis,然后也基于 AST 划分 BasicBlock ,调用 LLVM 进行代码生成。上述的流程是基于之前阅读 Clang 源码后凭记忆得出,同时也参考了 Github 上有人写过的 clang 流程分析,如有错误请不吝赐教。
naivecompiler 的框架设计
naivecompiler 中,前端的词法、语法、语义分析是用 Python 基于 PLY 框架实现的,后续的中间代码生成、和基于中间代码的分析也是基于 Python 实现。生成好中间代码后以序列化的方式生成中间文件,然后在 C++ 后读取序列化文件。代码生成以及后端的优化、目标文件生成都是在 C++ 中封装 llvm api 实现。
目录结构
naivecompiler git:(llvm-6.0) tree -C -L 1
.
├── Docker
├── README.md
├── Structure.py
├── analysis_handler.py
├── ast_rewrite.py
├── backend
├── build.sh
├── c_ast.py
├── c_parser.py
├── cfgbuilder.py
├── clean.sh
├── codegen.py
├── compiler.py
├── demo
├── interface.py
├── libNaiveScript.so
├── link.sh
├── llvm.py
├── ns.data
├── parser.out
├── parsetab.py
├── requirements.txt
├── serialize_handler.py
├── serialize_structure.py
├── symbol_table.py
├── test.sh
├── tests
└── visitor.py
其中,compiler.py 为整个项目的入口。编译的过程为:
- 调用
c_parser.py中的词法、语法分析模块,按c_ast.py生成 AST。 - 然后调用
codegen.py中的build_basic_blocks将 AST 按 basic block 划分,生成中间代码。 compile函数中调用SerializeHandler将 AST 序列化,并调用dump_stringtable将环境变量中的字符串表一同序列化生成最后的序列化文件。- 加载后端 c++ 链接库,读取序列化文件。
- 后端解析序列化文件,调用 LLVM API 生成 LLVM IR。
- 根据 IR 调用 LLVM API 生成对应的目标文件。
总结
在后续的几篇文章中,我们将陆续分前后端以 NaiveCompiler 和 Clang 为例介绍一个C语言子集的典型的静态编译器的各个部分,以及 PLY 和 LLVM 的使用和编译器编写中常用的模式和数据结构。
- 编译器开发从零单排(2) 中将介绍如何使用 PLY 进行词法、语法分析,生成 AST。
Refs
- https://norasandler.com/2017/11/29/Write-a-Compiler.html
- https://dsprenkels.com/compiler-construction.html